Observation
Both timers work
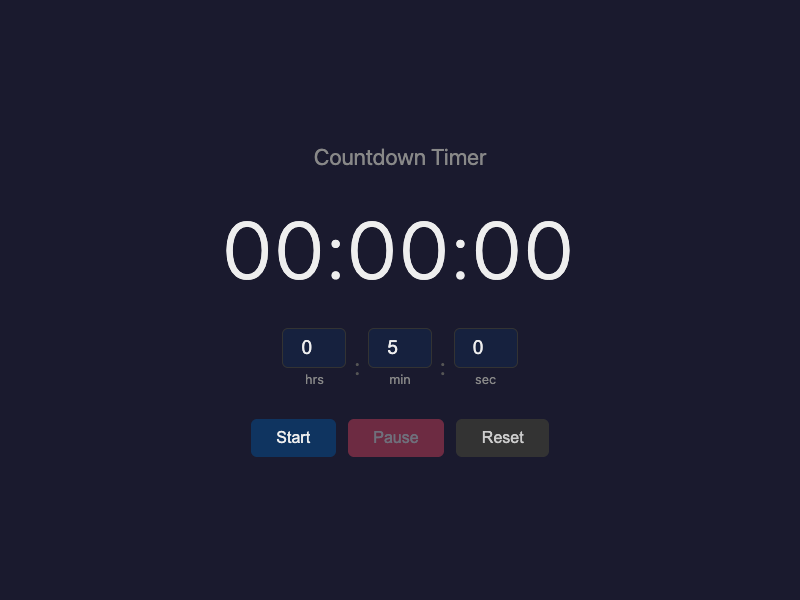
Let's start with what converged. Both branches built a countdown timer. Both use hours/minutes/seconds inputs. Both default to 5 minutes. Both have Start, Pause, and Reset buttons. Both turn the display red when the countdown hits zero. Both hide input fields while the timer is running.
If you opened both HTML files side by side, you would see two dark-themed countdown timers that do essentially the same thing. The product identity is perfectly preserved in both branches. This is not surprising — "countdown timer" is a genre with almost no ambiguity.
Where "simple" went
Here is where it gets interesting.
The prompt-only agent built a polished timer. It added a heading (`<h1>Countdown Timer</h1>`). It gave each button a distinct color: blue for Start, red for Pause, gray for Reset. The overall color scheme (`#1a1a2e`, `#0f3460`, `#e94560`) is attractive — a kind of midnight blue palette. It looks good.
The intent-driven agent built a plainer timer. No heading. All buttons use the same monochrome styling — dark background, light border, differentiated only by label. The color scheme (`#111`, `#1a1a1a`) is stark. It looks functional.
Neither agent did anything wrong. But they interpreted "simple" differently. The prompt-only branch treated "simple" as an aesthetic: *make it look clean*. The intent-driven branch treated "simple" as a constraint: *do not add anything that is not needed*.
The prompt-only agent's own summary is revealing on this point. It wrote: "Adding pause/reset goes beyond what 'simple countdown timer' strictly requires. These are conventional features but were not requested." The agent recognized that pause and reset were scope additions — and added them anyway, because they "felt expected." That is a perfectly reasonable decision. But it was made silently, without the agent surfacing the tension between "simple" and "conventional."
The intent-driven branch also added pause and reset. But the intent artifact had already justified their inclusion at 0.80 confidence, noted them as goals G4 and G5, and documented the rationale: "Pause/resume is a near-universal expectation for timers; omitting it would feel broken." The same decision, but made explicitly, with a confidence level attached.
The state machine difference
Under the hood, the two branches diverge more than they appear to on the surface.
The prompt-only branch manages state through implicit variables: a `running` boolean and a `remaining` counter. Whether the timer is paused, completed, or idle is determined by combinations of these variables and the presence or absence of an active interval. It works, but the state is distributed.
The intent-driven branch uses an explicit state variable: `let state = 'idle'`, with four named values — `idle`, `running`, `paused`, `completed`. A centralized `updateUI()` function renders everything based on the current state. The code even includes a comment mapping the state machine:
```
// State machine per EXO behavioral_semantics:
// idle -> running -> paused -> running (resume)
// -> completed -> idle (reset)
// paused -> idle (reset)
```
This is directly traceable to the intent artifact's `behavioral_semantics.state_machine` section. The intent artifact did not prescribe an implementation pattern — it described how the timer *behaves*. The agent then chose to mirror that behavioral model in the code structure.
This matters because the explicit state machine makes the code auditable against the intent artifact. You can ask: "Does the implementation's `completed` state match the artifact's definition of completion?" and point to specific lines. With the implicit-state version, the same question requires reconstructing the state from scattered variables.
Input validation
A small but telling difference: the intent-driven branch clamps input values to valid ranges (`Math.max(0, Math.min(99, ...))` for hours, similar for minutes and seconds). The prompt-only branch just does `parseInt(...) || 0`, which accepts any number the browser allows.
The intent artifact had flagged this as a forbidden state (FS4: "Input fields accepting non-numeric or negative values"). The intent-driven agent built the guard. The prompt-only agent did not think to.
This is a minor point for a countdown timer. But it illustrates how explicit forbidden states can surface defensive code that an agent would not generate from the prompt alone.
What the prompt-only agent did well
The prompt-only agent was more self-aware about its assumptions than many prompt-only branches we have seen. Its summary listed eight explicit assumptions it made, including "Pause and reset — the prompt said nothing about pausing or resetting. I added both because they felt expected for a timer, but this is scope I invented." It also listed seven clarification questions it thought of but did not ask.
This level of self-reflection is genuinely good. It suggests that the prompt-only approach is not blind — it is capable of recognizing its own silent decisions. The difference is that it recognized them *after* implementation, in a summary, rather than *before* implementation, in a binding artifact.
Drift Analysis
Primary: Constraint drift (mild)
The prompt-only branch exhibits mild constraint drift on the word "simple." The constraint word was not distorted dramatically — the timer is still simple in the colloquial sense. But "simple" was treated as aesthetic guidance rather than a scope rule. The heading, the colored buttons, and the styled dark theme represent investment in visual identity that goes slightly beyond what "simple" strictly requires.
This fits the drift taxonomy's definition: "Constraint words like 'simple' are reinterpreted loosely during implementation." The reinterpretation here is gentle — from "minimal scope" to "clean-looking" — but it is observable.
Secondary: Silent default selection
Both branches made silent default selections (dark theme, 5-minute default, HH:MM:SS format, no sound). The prompt-only branch did not surface these as meaningful choices during implementation — they appeared in the post-hoc summary. The intent-driven branch surfaced most of them during intent discovery (the scope exclusion list, the assumption section with confidence levels).
The most interesting silent default is the absence of sound. The prompt-only agent noted: "Many countdown timers beep or play a sound when they finish. I chose not to, partly to stay 'simple,' but this is a judgment call." The intent-driven artifact explicitly excluded sound in its scope section and justified the exclusion through the simplicity protected value. Same decision, different epistemic status.
Legitimate Divergence
Several differences between the branches represent valid design choices in areas the intent artifact did not constrain:
- Color palette: Dark blue-black vs. pure dark. The intent artifact specifies simplicity but not specific colors. Neither palette conflicts with protected values.
- Event binding: Inline `onclick` vs. `addEventListener`. The intent-driven summary explicitly flagged this as a legitimate divergence.
- Button differentiation: Color-coded vs. monochrome. Arguably the monochrome approach aligns more tightly with the simplicity protected value, but the colored approach does not violate any invariant.
- Heading presence: One has an `<h1>`, one does not. The page title serves identification in both.
A notable convergence: both branches independently chose a 5-minute default and HH:MM:SS input format. Neither was specified in the prompt. Both agents arrived at the same answer through convention, which suggests these defaults are genre expectations rather than intent questions.
Result
The hypothesis held, but more gently than expected. We predicted the prompt-only branch might treat "simple" loosely, and it did — but only mildly. There was no dramatic scope inflation, no feature creep, no product identity drift. Both agents built the right product.
The interesting finding is not about what was built, but about the *epistemic status* of the decisions that shaped what was built. Both agents made the same core decisions (pause, reset, no sound, dark theme, 5-minute default). The difference is that the intent-driven branch made those decisions explicitly, with confidence levels, rationale, and traceability — while the prompt-only branch made them implicitly, recognizing them only in retrospect.
The strongest single takeaway: on a prompt this simple, intent discovery does not change *what* gets built. It changes whether the decisions that shaped it are visible or buried.
Principle
Constraint words are the most dangerous part of a short prompt. The shorter the prompt, the more load-bearing each word becomes. A single adjective like "simple" can function as an aesthetic suggestion or as a scope rule, and the agent's interpretation of that word shapes the entire implementation posture. Intent discovery forces the interpretation to be made explicitly. Without it, the agent will choose an interpretation — often a reasonable one — but the choice will be silent.
A sharper formulation: *When a prompt is four words long, every word is a protected value. The question is whether anyone writes it down.*
Follow-Up
- Would a prompt with a stronger constraint word ("Build a *tiny* countdown timer" or "Build a countdown timer with *no extra features*") produce larger divergence between branches?
- On a more complex prompt with genuine ambiguity, does the structural difference (explicit state machine vs. implicit booleans) scale into a meaningful auditability advantage?
- The prompt-only agent's post-hoc self-reflection was unusually strong. Does asking a prompt-only agent to write its assumptions summary *before* implementation (but without a structured artifact) close the gap with intent discovery?
Limitations
- Single run. Both branches were implemented once. Variance across runs is unknown.
- Same model family. Both branches used the same underlying model, which means shared training biases could explain convergence.
- Analytical comparison. Differences were assessed by reading code and summaries, not by running automated tests or user studies. Claims about "auditability" are based on code structure inspection, not measured audit performance.
- Minimal prompt. The prompt is so simple that the experiment may understate the value of intent discovery. On a prompt with genuine ambiguity or domain complexity, the differences could be larger — or smaller. We cannot generalize from this single data point.
- Constraint drift is mild. Classifying the prompt-only branch's visual choices as "constraint drift" is a judgment call. A reasonable person could argue that colored buttons and a heading are within the bounds of "simple." The classification is honest but debatable.
- Shared genre knowledge. "Countdown timer" is a well-understood product category. Both agents drew on the same genre conventions, which compressed the space for divergence. On a more novel product concept, the branches might diverge more.