Observation
The naming tells the story
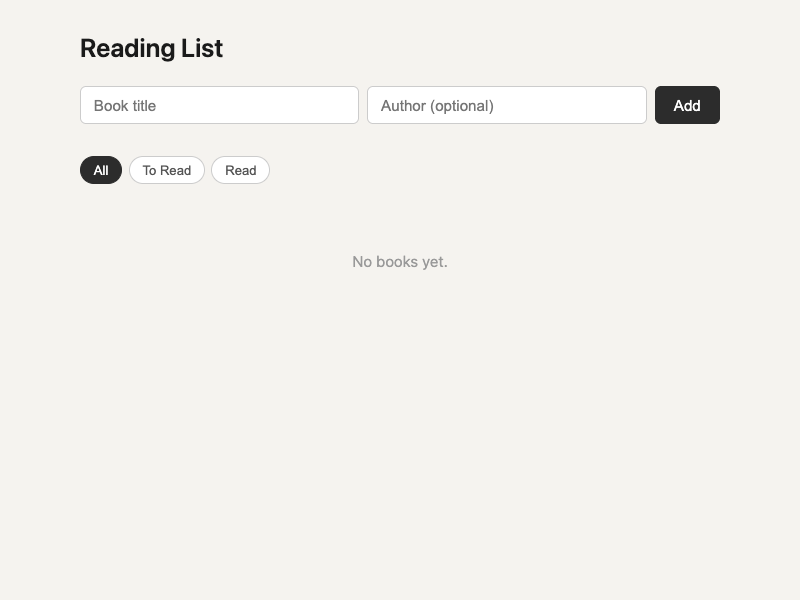
Open the prompt-only branch's source code and you see: `book-item`, `book-title`, `book-author`, `addBook()`, `deleteBook()`, `toggleRead()`. The product has been named: it is a book tracker.
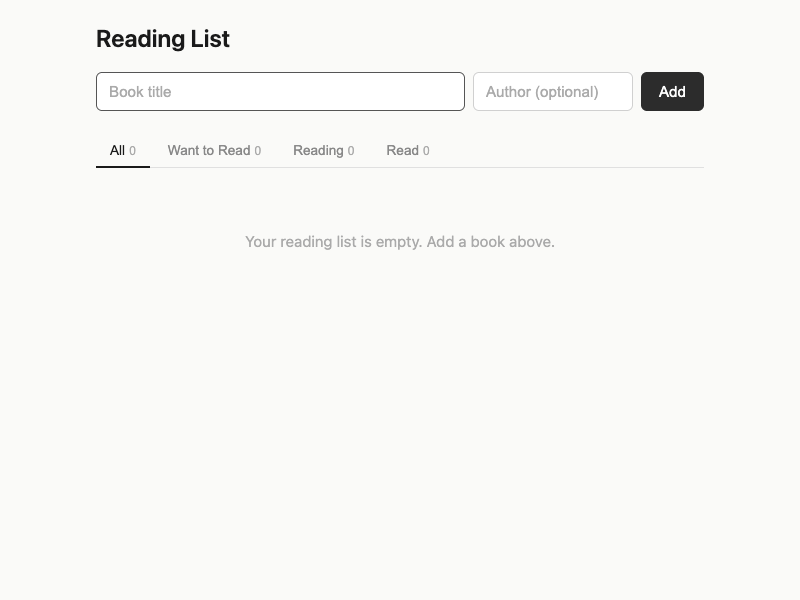
Open the intent-driven branch and you see: `item-info`, `item-title`, `item-author`, `addItem()`, `deleteItem()`, `setStatus()`. The product has been named differently: it is a list of reading items.
This is not a cosmetic difference. The prompt says "reading list app." It does not say "book." The prompt-only agent made a reasonable assumption -- reading lists usually contain books -- but that assumption was made silently, and it narrowed the product's identity. An article, a paper, a blog post series: these are all things you might put on a reading list. The prompt-only branch's naming makes them feel like they do not belong.
The intent artifact flagged this risk explicitly (DR1: "The app becomes a book catalog or library manager, organized around rich book records instead of a simple reading queue"). The intent-driven branch avoided it.
The checkbox and the status badge
The most consequential design difference is in how reading progress is modeled.
The prompt-only branch uses a checkbox. You add a book, and later you check the box to mark it as read. The checked items get a strikethrough. This is a binary: unread or read.
The intent-driven branch uses color-coded status badges. Each item shows its state -- "Want to Read" in blue, "Reading" in yellow, "Read" in green. Click the badge and a dropdown offers all three options. You can move items forward (queued to reading to finished), backward (re-read something), or skip states (mark something as read without going through "reading" first).
The prompt-only agent acknowledged this choice in its own summary: "The prompt says 'reading list,' not 'reading tracker.' A list could just be a list, with no status tracking." And then it chose a binary model anyway.
That last sentence is worth sitting with. The agent saw the ambiguity, articulated it clearly, and then resolved it silently in the simplest direction. There is no evidence that the choice was wrong -- a binary model is defensible. But the choice was made without surfacing it as a design decision that the user might care about.
The intent artifact, by contrast, made this a first-class design question. Goal G2 states: "Let the user track reading progress through simple status changes." The confidence was set at 0.85 -- not certain, because the prompt does not explicitly require status tracking. But the artifact treated the three-state model as the minimum useful progression and the implementation followed that guidance.
Data integrity: the quiet gap
Both branches save to localStorage on every mutation. But the intent-driven branch does two things the prompt-only branch does not.
First, it validates data on load. When the app starts, it parses localStorage and filters out any items with missing titles or invalid statuses. If localStorage contains corrupted data -- a plausible scenario after browser updates, storage quota issues, or manual tampering -- the prompt-only branch would attempt to render invalid data (potentially crashing), while the intent-driven branch would silently discard the bad entries and continue.
Second, the intent-driven branch wraps the save operation in a try-catch. If localStorage is full or unavailable, it alerts the user: "Could not save your reading list. Storage may be full." The prompt-only branch would fail silently -- the user would keep adding items, believing they were saved, only to discover on reload that their list was incomplete.
These are not headline features. They are the kind of edge-case handling that users never notice until they need it. The intent artifact made data integrity a protected value (PV3) and flagged silent data loss as a critical failure boundary (FB1). That explicit framing turned an easy-to-skip concern into a design obligation.
The checkbox as product identity
There is a subtler observation worth making about the checkbox interaction. A checkbox is a completion marker. It says: this task is done. The mental model it invokes is a todo list -- items exist to be completed and crossed off.
A reading list is not really a todo list. It is a queue of intentions. Some things on it you will read soon. Some you are reading now. Some you finished months ago but want to keep on the list because the list itself is meaningful -- it represents your reading life, not just your reading backlog.
The checkbox framing subtly pushes the product toward task management. The status-badge framing preserves the reading-list identity, where items are in different stages of a personal reading journey rather than being "done" or "not done."
The intent artifact flagged this as drift risk DR3: "The app shifts from supporting the practice of reading (tracking what to read next) to managing information about books (metadata, covers, reviews)." The checkbox does not go as far as metadata management, but it does reframe reading completion as task completion, which is a mild form of the same drift.
Drift Analysis
Primary: Silent default selection
The prompt-only branch chose a binary status model without surfacing the decision. The agent recognized the ambiguity ("a list could just be a list, with no status tracking") but resolved it without treating it as a meaningful design choice. This is textbook silent default selection -- the agent picks a reasonable default in an ambiguous area without flagging that alternative interpretations exist.
Secondary: Product-identity drift (mild)
The prompt-only branch's naming convention (`book-*`, `addBook`, `deleteBook`) narrows the product from "reading list" to "book list." This is a mild form of product-identity drift: the implementation assumes a more specific product category than the prompt specifies. A reading list could contain articles, papers, blog posts, or any textual work. The book-specific framing excludes these without acknowledging the narrowing.
Tertiary: Practice-to-tool drift (mild)
The checkbox interaction pattern reframes reading completion as task completion. This is a mild instance of practice-to-tool drift: the lived activity of reading (with its natural progression from intention through engagement to completion) is compressed into a binary task-management interaction. The drift is subtle and the prompt-only branch is not seriously damaged by it, but it represents a shift in how the product relates to the user's experience.
Legitimate Divergence
Several differences between the branches are valid design choices in areas the intent artifact did not constrain:
Visual palette. The prompt-only branch uses a warmer neutral (#f5f3ef), while the intent-driven branch uses a cooler neutral (#fafaf8). The intent artifact allows visual styling as an optimization area. Neither choice conflicts with any protected value.
Filter tab styling. Pill-shaped buttons (prompt-only) vs underline tabs (intent-driven). Both provide status filtering. The interaction pattern is a UI convention choice that the artifact does not constrain.
New item placement. The prompt-only branch appends new items to the bottom of the list. The intent-driven branch prepends them to the top. The artifact does not specify ordering, and both choices are defensible for a reading list.
Counter display. The prompt-only branch shows "X unread of Y books" at the bottom. The intent-driven branch shows per-status counts in the filter tabs. Both provide useful summary information in different ways.
Convergence worth noting. Both branches independently chose: single HTML file with no framework, localStorage, title + optional author as the data model, filter tabs, delete via x button, Enter key to add, and XSS-safe escaping. This convergence suggests the prompt carries enough signal to anchor the basic product shape even without an intent artifact.
Result
The hypothesis held. The prompt-only branch did collapse reading status into a binary model, exactly as predicted. It also drifted mildly on product identity (book tracker rather than reading list) and interaction framing (task completion rather than reading progression).
But the more interesting finding is not in the features. Both branches built a working reading list app. Both look clean. Both persist data. A user could happily use either one.
The interesting finding is in the quality of silence. The prompt-only branch made at least three design decisions silently: the binary status model, the book-specific product identity, and the absence of data validation. The intent-driven branch made those same decision points visible through the artifact and then resolved them deliberately.
The prompt-only agent even demonstrated awareness of the ambiguity -- its summary explicitly notes that a reading list might not need status tracking, that "reading list" might mean articles rather than books, and that persistence is an assumption. But awareness did not become constraint. The agent saw the choices and made them anyway, without letting the user weigh in.
The strongest single-sentence takeaway: An agent that recognizes ambiguity is not the same as an agent that treats ambiguity as a design decision.
Principle
When a prompt contains a familiar concept ("reading list"), agents resolve its ambiguities from convention rather than from the prompt itself. Intent discovery does not prevent agents from making design choices -- it prevents them from making those choices silently. The value is not in the answers the artifact provides, but in the questions it forces to be asked before implementation begins.
A stronger formulation: Familiarity is a drift vector. The more recognizable a prompt concept is, the more likely an agent is to substitute convention for intent -- and the less likely it is to notice the substitution.
Follow-Up
- Would a prompt that says "reading tracker" instead of "reading list" change the prompt-only branch's status model? Testing whether a single word shift changes the agent's default resolution would help calibrate how sensitive product identity is to prompt phrasing.
- If the prompt said "Build a simple reading list app," would the prompt-only branch produce a simpler or more complex result? The word "simple" might trigger constraint drift rather than actual simplification.
- Would regenerating the intent-driven implementation from the same artifact (without seeing the first implementation) produce a similar three-state status model? This would test whether the artifact carries the status-model decision strongly enough to survive regeneration.
Limitations
- Single run. Each branch was implemented once. The prompt-only branch might produce a three-state model on a different run. The observed drift is a single data point, not a guaranteed pattern.
- Same model family. Both branches used the same underlying model, which means shared training biases could affect both branches similarly. A different model might resolve the status-model ambiguity differently.
- Analytical comparison. All findings are based on code inspection and agent self-reports, not on user testing or automated verification. Claims about "task completion framing" and "reading progression" are interpretive.
- Context volume confound. The intent-driven branch received substantially more input context (the YAML artifact). Some of the observed differences could be attributed to the additional context volume rather than to the structural content of the artifact. The fact that the prompt-only agent identified similar ambiguities in its summary but did not act on them suggests the structure matters, but this is not conclusive.
- Drift severity. The observed drifts are mild. The prompt-only branch is a usable reading list app. Calling its choices "drift" rather than "legitimate design decisions" involves judgment. A reader who prefers the checkbox model would reasonably disagree with the drift classification.